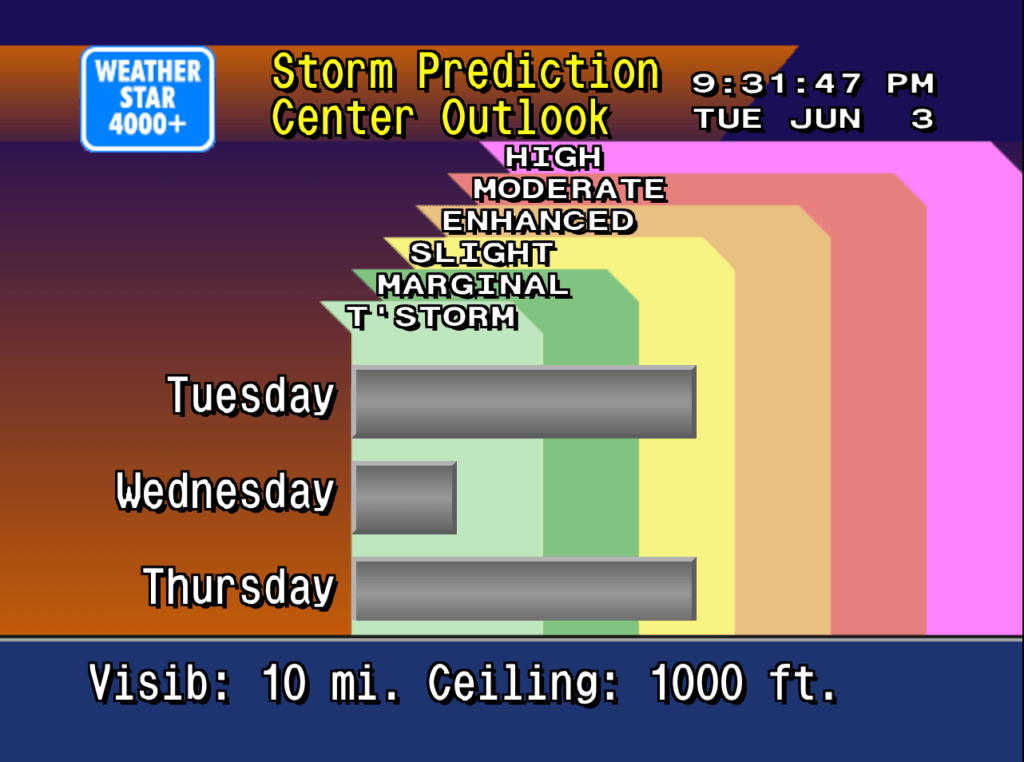
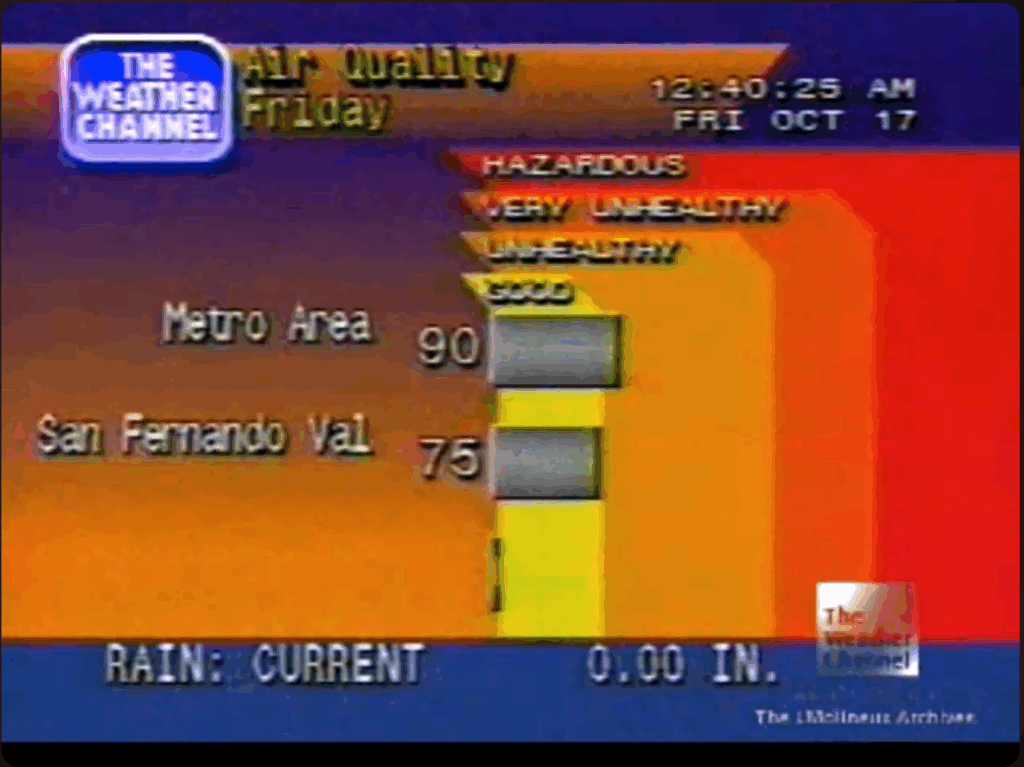
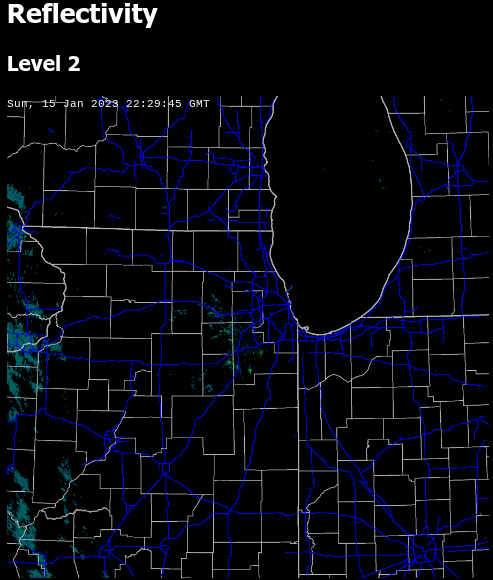
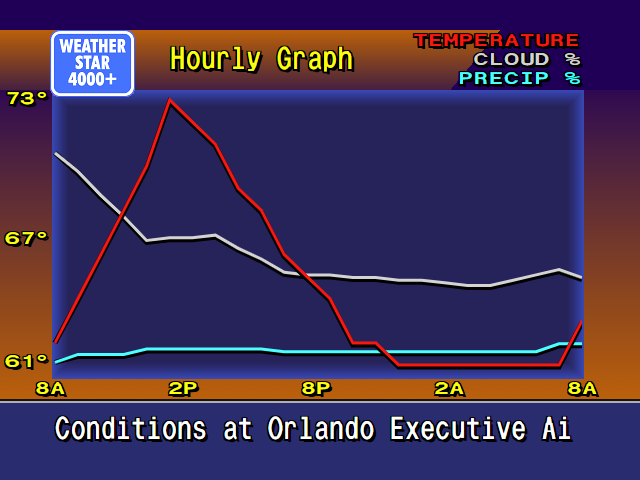
Retroist recently wrote a great history and discussion of the Weatherstar and the nostalgia that surrounds it. It’s really a great read. The Weatherstar 4000, Then and Now.
The article sparked a memory related to the Weather Channel and Cable TV that I wanted to share. In the heyday of cable TV and our favorite local forecasts in the mid 90’s you might occasionally have to go into the cable company office in your town. Some would even pay their bill in person this way if they didn’t want to mail a check each month. I was in grade school at the time and remember going in there just a few times.
To most this visit was uneventful and pretty boring. You’d walk into the building beside large satellite dishes pointed at various places in the sky. These are what brought in TBS, The Discovery Channel, WGN, CNN, HBO and plenty of other channels from all over the country. The astute observer may even notice the antenna mast on top of the building with smaller antennas pointed in different directions to pick up your local network stations like NBC, ABC or your PBS affiliate.
The building was a necessity to house all of the hardware associated with delivering cable TV. They just happened to have a desk inside the front door where you could talk to someone about your service or pay your bill. They were also the ones who answered the phone if you called, often in just 1 or 2 rings! The office in my hometown showcased some of their technology. Behind the desk was a glass wall, and behind that glass wall what what I now know are 19″ racks that housed all of the cable TV equipment.
I’d stare past the desk at all of the blinking lights and cables. I recall a lot of 2U black boxes (I only now know the sizes) that had those plastic, wood-grain labels with white lettering embossed on them. The labels called out channel numbers and networks like “22 Nickelodeon”. There was one box in that rack that stood out. It was twice as tall, white and had a large blue rectangular logo of the Weather Channel on it.

This image comes from Hackaday where you can read how Tom Nardi resurrected this piece of cable TV history. it’s the exact box I remember seeing behind the desk at the cable company’s office. And because it was bigger and different I knew something special was happening inside of it. I already watched the weather channel all the time. I realized the local forecast was something special that no other channel in those 40-some we had available could do. And to see this box in person just further peaked my interest in The Weather Channel and the technology behind it.
Thirty years later I’m still very interested in these memories from the 90’s and am very glad that I live in a time where it’s possible to recreate the look and feel of what Retroist calls “genuinely well-designed.” The internet and web browsers are what make this possible. But the internet also allows the retro weather community to share old videos, discuss their memories, and collaborate on the details of this project and the add-on projects such as the international version and the streaming ws4channels implementation. It’s the community around this that is so much fun to be a part of.
Upcoming WS4KP Enhancements
For those of you still reading I have some exciting Weatherstar news. There will soon be 2 new modes what Ws4kp can run in. The enhanced modes will add more data to the classic displays. Enhanced widescreen displays will show more days into the future, wider maps or just make better use of the letterbox space. And a new enhanced portrait mode rotates the screen and lays out the graphics is the same style, but making much better use of the space vertically. Larger maps, more nearby weather stations and more days in the extended forecast are just some of the upgrades.

I will stick with my no-fuss way of running this and for nostalgia first time users will continue to see the 4:3 original graphics with the newer modes optionally available. You can find out more, including some links to a preview, in the discussions and issues on github.
Thank you for supporting the Ws4kp project and for your interest in this community and nostalgia.